用于游戏的前沿开源生成式AI模型
关于生成式AI有件事——多年来,最好的模型都躲在API Key和无法预测的定价后面。你围绕一个工具搭好工作流,用得顺手了,第二天醒来邮件来了:定价变了。或者更糟,公司整个转型了。
2024年底情况变了。腾讯、阿里、DeepSeek——他们开始放出你真能下载的模型。能和闭源对手掰手腕的模型。突然之间,创作者有了不依附于别人商业模式的选择。
如果你能从自己控制的模型生成视频、3D资源、音乐和声音呢?我们现在就在这个时刻。这份指南讲清楚什么是真的、什么能用、你今天就能开始用什么。
视频生成
多年来,视频生成意味着Runway或Pika——闭源平台、订阅费、对输出用途的各种限制。现在呢?你能在自己的硬件上跑同档次的模型。
HunyuanVideo 文生视频生成——领先开源视频模型的720p输出
| 模型 | 机构 | 参数 | 规格 | 硬件 | 成本 |
|---|---|---|---|---|---|
| HunyuanVideo | 腾讯 | 13B | 720p,文+图 | 80GB | ~$0.20 |
| Mochi 1 | Genmo | 10B | 480p@30fps | 12GB+ | ~$0.10 |
| LTX-Video | Lightricks | — | 768x512,实时 | 12GB | ~$0.02 |
| LTX-2 | Lightricks | 19B | 4K,音画同步 | 高端 | ~$0.30 |
| Wan 2.1 | 阿里 | 1.3-14B | 480p-720p | 8GB+ | ~$0.03 |
| CogVideoX | 清华 | 5B | 720x480@8fps | 12GB | ~$0.04 |
| Open-Sora 2.0 | HPC-AI | 11B | 整合Flux | 高端 | ~$0.20 |
权重:HunyuanVideo ↗ · Mochi 1 ↗ · Wan 2.1 ↗ · Open-Sora ↗
看样例: HunyuanVideo 画廊 ↗ · Mochi 示例 ↗ · CogVideoX 样例 ↗
这对创作者意味着什么
HunyuanVideo 在专业评测中胜过Runway Gen-3——而且完全开源。代价?你需要严肃的硬件。一块A100或H100,80GB显存。对大多数人来说,这意味着按需租云GPU。
Mochi 1 是你真能跑起来的那个。12GB显存——也就是RTX 3060档——就能搞定。输出真的有创意,有独特的艺术质感。保真度比不上HunyuanVideo,但流程你自己掌控。
LTX-2 是对游戏来说有意思的那个。它是第一个能生成与视频同步音频的开源模型。想象一下过场动画里声音就……正好对上。不用后期同步。权重在2025年晚些时候发布。
Wan 2.1 在游戏本上能跑。8GB显存可以跑小版本。如果你一直想用视频生成做原型但又没法投入硬件,这就是你的入门路径。
合理的工作流:本地用Mochi 1或Wan 2.1做原型。需要最终质量时上云用HunyuanVideo。
图像生成
这是开源已经赢了的领域。你今天能下载的模型,真的能和Midjourney竞争。不是"差不多好",是确实有竞争力。
 FLUX.1 样例——Apache 2.0许可证的照片级真实质量
FLUX.1 样例——Apache 2.0许可证的照片级真实质量
| 模型 | 机构 | 发布 | 参数 | 关键特性 | 许可证 | 单图成本 |
|---|---|---|---|---|---|---|
| FLUX.1 [schnell] | Black Forest Labs | 2024年8月 | 12B | 4步生成,速度快 | Apache 2.0 | ~$0.001 |
| FLUX.1 [dev] | Black Forest Labs | 2024年8月 | 12B | 质量接近Pro | 非商用 | ~$0.002 |
| SD 3.5 Large | Stability AI | 2024年10月 | 8B | 文字渲染、多样化风格 | Stability许可证 | ~$0.002 |
| SD 3.5 Large Turbo | Stability AI | 2024年10月 | 8B | 4步,速度快 | Stability许可证 | ~$0.001 |
| CogView4 | 清华 | 2025年3月 | 6B | 原生中文 | 开源 | ~$0.002 |
直接试用:FLUX.1 schnell demo ↗ · SD 3.5 Large demo ↗ · GitHub (FLUX) ↗
看样例: FLUX 画廊 ↗ · FLUX LoRA 画廊 ↗ · Replicate 示例 ↗
用来做游戏资源
FLUX.1 [schnell] 是必须知道的那个。Apache 2.0许可证——意味着你可以把它用在商业游戏里而不用担心许可证麻烦。生成只要4步,所以你可以快速迭代。描述你想要的,看结果,调整,重复。
SD 3.5 Large 终于能像样地渲染文字了。早期版本会把你想加的任何文字都搅成一团。这对UI Mockup、游戏内招牌、标题画面都很重要——任何需要可读文字的图像。
围绕Stable Diffusion的生态系统依然无可匹敌。ControlNet做精确构图、Inpainting做修补、LoRA微调做自定义风格。FLUX正在追,但如果你今天就需要深度自定义,SD的工具成熟度能给你更多空间。
我会这么想:贴图和Sprite,两个都行。需要特定风格的概念图,用带LoRA的SD 3.5。商业出货的纯质量,用FLUX schnell。
3D 生成
如果你花过8小时建一个道具,结果在游戏里只出现3秒,这一节是给你的。3D生成在2024年从"有意思的研究"变成了"真的能用"。你现在能从一张草图到一个带贴图的Mesh,不到一分钟。
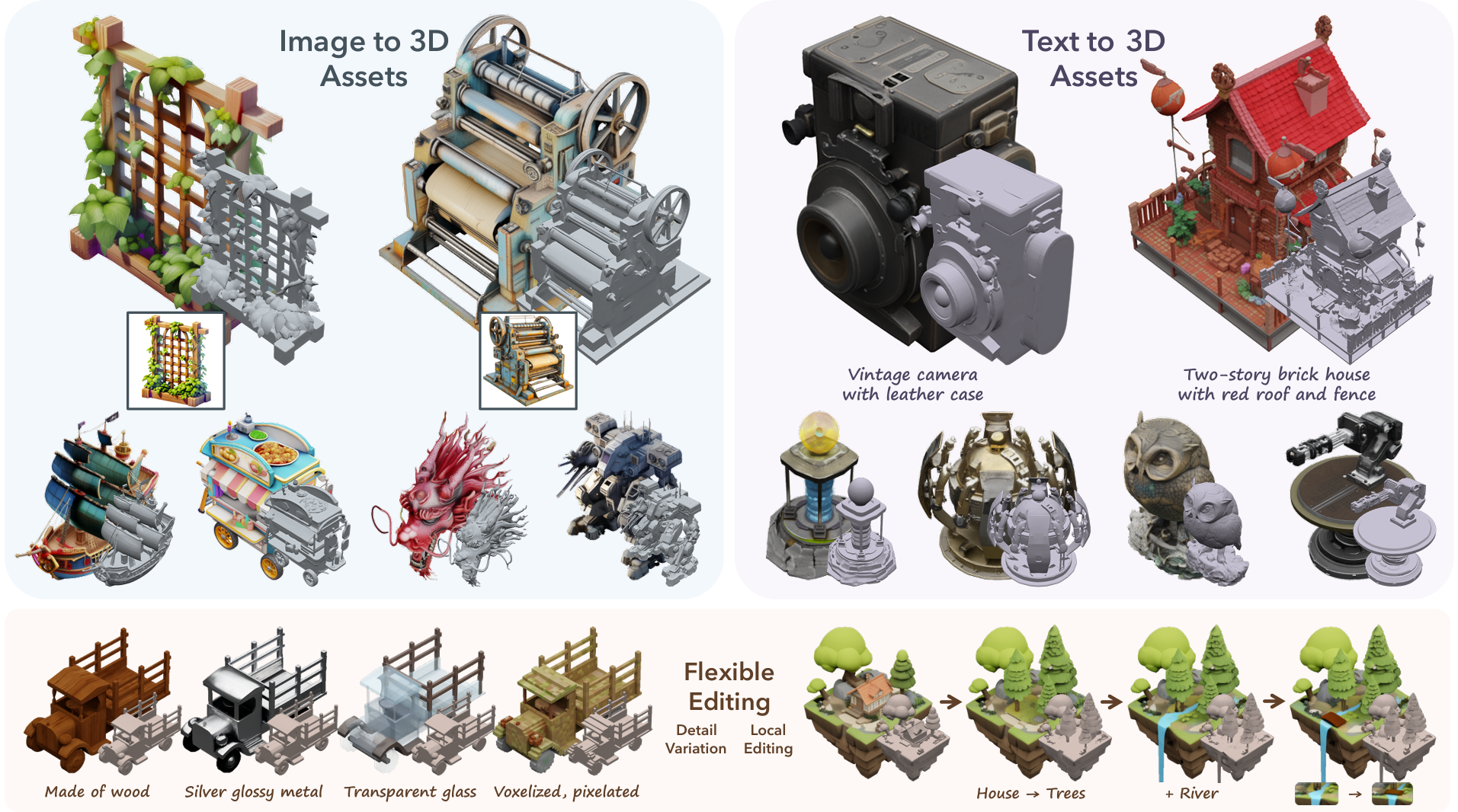 TRELLIS 从单张图像生成带PBR材质的纹理3D Mesh
TRELLIS 从单张图像生成带PBR材质的纹理3D Mesh
| 模型 | 机构 | 发布 | 关键特性 | 输出 | 单Mesh成本 |
|---|---|---|---|---|---|
| TRELLIS 2 | 微软 | 2025 | 4B参数,PBR材质 | 带法线的纹理Mesh | ~$0.03 |
| Hunyuan3D 2.0 | 腾讯 | 2025年1月 | 两阶段DiT | 高保真纹理Mesh | ~$0.05 |
| TripoSR | VAST/Stability | 2024年3月 | 单图 → 0.5秒出Mesh | Mesh(无贴图) | ~$0.001 |
| InstantMesh | TencentARC | 2024年4月 | 多视角扩散 | 高质量Mesh | ~$0.02 |
| Stable Zero123 | Stability AI | 2024 | 新视角合成 | 多视角图像 | ~$0.01 |
直接试用:TRELLIS 2 demo ↗ · Hunyuan3D demo ↗ · InstantMesh demo ↗
看样例: TRELLIS 2 项目页 ↗ · 3D AI Studio 画廊 ↗
一个真正跑得通的工作流
创作者现在玩出味道的做法是把模型串起来。从一张图像开始——生成的或拍的都行。让Stable Zero123或Wonder3D给你多视角。把这些视角喂给InstantMesh或TripoSR做Mesh。然后用TRELLIS 2或Hunyuan3D做正经的材质。
TRELLIS 2 来自微软,是生产就绪资源的新霸主。它能处理其他模型搞砸的几何——薄面、孔洞、复杂拓扑。4B参数版本输出的Mesh带真正的PBR贴图,不是用顶点色假装材质。
TripoSR 主打速度。从图像到Mesh只要半秒。Mesh需要清理和贴图,但作为原型呢?作为你在投入几小时前先验证想法的工具?无敌。
Hunyuan3D 2.5(即将发布)专注于"仿真就绪"的资源。游戏道具能直接在物理引擎里用,不用手工修。不会再出现因为Mesh拓扑奇怪而导致的隐形碰撞问题。
对独立创作者的现实期望:用FLUX生成概念图,用InstantMesh出几何,然后在Blender里做贴图或用TRELLIS自动出PBR。每个资源30-60分钟,而不是4-8小时。不是零成本,但确实是真正的差距。
音频与音乐
音频生成还没赶上图像和视频。但这里有足够多的东西能改变你的工作方式——尤其是原型和音效。
AI生成音乐样例——描述你想要的情绪,得到契合的音乐
| 模型 | 机构 | 发布 | 做什么 | 许可证 | 30秒成本 |
|---|---|---|---|---|---|
| YuE | MAP | 2025年1月 | 从歌词出完整歌曲,含人声+伴奏 | Apache 2.0 | ~$0.05 |
| MusicGen | Meta | 2023 | 文生音乐,可控 | MIT | ~$0.01 |
| AudioGen | Meta | 2023 | 音效、环境音 | MIT | ~$0.01 |
| Stable Audio Open | Stability AI | 2024 | 最长47秒样本 | 研究用 | ~$0.02 |
直接试用:MusicGen demo ↗ · AudioCraft playground ↗
看样例: MusicGen 示例 ↗ · AudioGen 样例 ↗
真能用在出货游戏里的
MusicGen 来自Meta,是游戏音频的实用选择。描述你想要的情绪,得到契合的音乐。MIT许可证意味着你能发布。3.3B模型在12GB GPU上跑得动——描述、生成、迭代。
AudioGen 处理音效:脚步声、门吱呀声、风声、机械声。一样的情况——MIT许可、本地运行、真的能填满你游戏的声音空间。
YuE 真的让人激动。它是第一个能生成带人声完整歌曲的开源模型。主题曲、有真唱的背景音乐。质量参差不齐,但比任何你能自己下载运行的东西都强一大截。
Stable Audio Open 有限制——47秒片段、仅限研究的许可证。适合原型想法,不适合出货。
老实说:开源和闭源(Suno、Udio)在音乐上的差距确实还在。对音效来说,开源是有竞争力的。要出货的完整歌曲,你得做大量迭代——或者请音乐人做最终制作,把这些工具用在其他所有地方。
语音
语音生成在2024年跨进了"对游戏来说够用"的区间。这改变了小团队能做什么。
AI生成的游戏旁白——节奏和情绪都到位的自然语音
| 模型 | 机构 | 发布 | 关键特性 | 许可证 | 单分钟成本 |
|---|---|---|---|---|---|
| CSM | Sesame AI | 2025年3月 | 对话节奏、自然停顿 | 开源 | ~$0.005 |
| Fish Speech 1.5 | Fish Audio | 2024 | 10-30秒零样本克隆 | Apache 2.0 | ~$0.002 |
| OpenVoice V2 | MyShell/MIT | 2024年4月 | 情绪/口音控制 | MIT | ~$0.003 |
| XTTS-v2 | Coqui(社区) | 2024 | 17种语言、声音克隆 | CPML | ~$0.005 |
听样例: Fish Audio 声音 ↗ · OpenVoice demo ↗
让NPC听起来像人
CSM(Conversational Speech Model) 来自Sesame,专门为对话设计。它会产生自然的停顿、语调变化、真实对话的节奏。大多数TTS听起来像是有人在念稿——一耳朵就听出来。CSM听起来像是有人在说话。这个差别比你想象的更重要。
Fish Speech 和 OpenVoice 处理声音克隆。录10-30秒的配音演员声音,然后用那个声音生成无限对话。想想这意味着什么:你可以请配音演员录关键台词,再延伸出几百个变体和环境对话。
NVIDIA ACE(不是完全开源,但值得了解)现在支持Qwen3-8B做端上NPC部署。本地LLM + 本地TTS + 口型同步——全部在消费级GPU上跑。这是实时NPC对话不依赖云调用的技术栈。
对独立创作者合理的做法:主要角色和最重要的台词请真人配音演员。用Fish Speech或OpenVoice延伸覆盖环境对话、变体台词,以及那些原本要么是沉默、要么贵到做不起的零碎台词。
世界模型与游戏仿真
这里事情开始变得真的怪——也真的让人激动。这些模型不是生成静态资源。它们生成感觉像游戏的体验。
🎮 玩 Oasis —— AI 生成的 Minecraft没有游戏引擎的实时世界生成,只有AI预测
| 模型 | 机构 | 发布 | 做什么 | 状态 | 单帧成本 |
|---|---|---|---|---|---|
| DIAMOND | 研究 | 2024 | 扩散世界模型,Atari仿真 | 开源权重 | ~$0.001 |
| Oasis | Decart/Etched | 2024年10月 | 实时Minecraft生成 | 500M权重开放 | ~$0.002 |
| GameGen-X | 研究 | 2024 | 开放世界视频生成 | 代码+数据集开放 | ~$0.005 |
| NVIDIA Cosmos | NVIDIA | 2025年1月 | 物理AI仿真 | 开源权重 | ~$0.01 |
| Genie 2 | DeepMind | 2024年12月 | 从图像出可交互3D | 未发布 | N/A |
看研究:DIAMOND 项目页 ↗ · Cosmos 博客 ↗
试用: Oasis 在线demo ↗ · Genie 2 示例 ↗
为什么你应该关心这个
DIAMOND 证明了一件改变你对游戏AI想法的事。你可以完全在一个生成的世界里训练智能体。训练根本不需要真正的游戏引擎。AI在扩散模型的想象里玩——然后迁移到真实游戏。这里的含义意义重大。
Oasis 实时跑一个类Minecraft世界。一帧一帧。没有游戏引擎、没有贴图、没有预制资源。只是一个Transformer在预测下一步会出现什么。这是个概念验证,但想想它会走到哪里。500M参数版本已经开放。
GameGen-X 发布了开放世界游戏视频最大的数据集。如果你想训练自己的模型,或者微调现有模型来生成类游戏内容,这是你的起点。
NVIDIA Cosmos 为机器人和自动驾驶而建,但世界基础模型对游戏也有用。它们理解物理、对象恒常性、空间关系。开源权重,宽松许可。
对今天的实际游戏开发,这些还是研究工具。但如果你在做AI驱动的内容、过程化生成,或只是在想这一切会走向哪里——这就是前沿。
大语言模型
LLM驱动对话、任务生成和游戏逻辑。开源选项现在真的能和GPT-4竞争。两年前不是这样。
| 模型 | 机构 | 发布 | 大小 | 最适合 | 许可证 | 1K token成本 |
|---|---|---|---|---|---|---|
| DeepSeek-V3 | DeepSeek | 2024年12月 | 671B MoE(激活37B) | 推理、通用 | 宽松 | ~$0.02 |
| DeepSeek-R1 | DeepSeek | 2025年1月 | 基于V3 | 链式思考 | 宽松 | ~$0.03 |
| Qwen3 | 阿里 | 2025 | 235B MoE(激活22B) | 多语言、代码 | Apache 2.0 | ~$0.01 |
| Llama 4 | Meta | 2025 | 多种规格 | Agent、128k上下文 | Llama社区 | ~$0.01 |
| DeepSeek Coder V2 | DeepSeek | 2024 | — | 300+种语言 | 宽松 | ~$0.01 |
| Qwen2.5-VL | 阿里 | 2025年1月 | 7B-72B | 视觉+语言 | 宽松 | ~$0.02 |
入门:HuggingFace上的Qwen3-8B ↗ · HuggingFace上的DeepSeek-V3 ↗
用于做游戏
Qwen3 是大多数游戏用途的实用选择。Apache 2.0许可证——你的集成由你做主。多语言支持强,如果你在想本地化,这点很重要。擅长跟随结构化指令。7B和14B变体在消费级GPU上能本地跑。
DeepSeek-V3 在多数基准上达到或超过GPT-4。架构很聪明——尽管总参数671B,每个token只激活37B。你需要严肃硬件(多GPU),但质量是前沿级,不依赖API。
Qwen2.5-VL 加入了视觉理解。对需要分析截图、理解玩家手绘内容或处理摄像头输入的游戏有用。7B变体单GPU能跑。
对端上NPC——实时响应、不调云的角色——通过NVIDIA ACE跑 Qwen3-8B 是现在最实用的路径。它和你的游戏一起跑在玩家硬件上。
工具类模型
这些不直接生成内容——但它们让你的Pipeline跑得通。
 SAM 2 分割图像和视频里的任何对象——点一下,得到完美Mask
SAM 2 分割图像和视频里的任何对象——点一下,得到完美Mask
| 模型 | 机构 | 发布 | 做什么 |
|---|---|---|---|
| SAM 2 | Meta | 2024年8月 | 分割图像和视频里的任何东西 |
| Depth Pro | Apple | 2024年10月 | 单图出度量深度 |
| gsplat | Nerfstudio | 2024+ | 高斯泼溅,CUDA加速 |
SAM 2 在视频中实时分割对象。点一下,得到完美Mask。对Rotoscoping、合成或从素材里抠出对象用作游戏资源都有用。试用 SAM 2 ↗
Depth Pro 来自Apple,从单图在一秒内出度量深度图。这解锁了很多:把2D艺术转成带视差的2.5D、为3D重建生成深度数据、从平面图像生成法线贴图。HuggingFace上的Depth Pro ↗
gsplat 是高斯泼溅的高速实现。如果你在为游戏捕获真实环境——摄影测量、环境扫描——这是让事情变得可行的库。
我真正会用什么
如果你今天开始一个游戏项目,这是合理的技术栈:
贴图和Sprite:FLUX.1 [schnell]——Apache 2.0、快速迭代、能出货的质量
概念图:SD 3.5 Large 加 LoRA 控制风格
3D资源:InstantMesh出几何,然后Blender做贴图,或TRELLIS 2自动出PBR
音效:AudioGen——MIT许可、本地跑、填满你的声音空间
音乐:MusicGen做原型,然后请作曲家做最终制作
语音:Fish Speech做原型,配音演员加克隆做生产
NPC对话:本地Qwen3-8B,或者复杂推理用云LLM
视频(过场):本地Mochi 1,需要最终质量时上云用HunyuanVideo
关于这一切有件事:常见的错误是想把AI用在所有事情上。这些是工具,不是替代品。它们把繁琐的部分压缩——迭代、变体、占位资源——好让你把时间花在真正重要的创意决策上。让你的游戏成为你的游戏的那部分。
硬件现实
实话讲讲跑这些东西你真正需要什么:
8GB显存(RTX 3060、4060):SD 1.5/SDXL、Wan 2.1小版本、AudioGen、Fish Speech、小LLM(7B量化)。这是游戏本档——已经够入门。
12GB显存(RTX 3080、4070):SD 3.5、FLUX schnell、Mochi 1、MusicGen、TripoSR、Qwen 14B量化。到这里就舒服了。大多数有用的模型都能跑。
24GB显存(RTX 3090、4090):大多数模型全精度、InstantMesh、更大的LLM。如果你认真要做这套工作流,这是甜区。
48-80GB显存(A100、H100):HunyuanVideo、LTX-2、DeepSeek-V3、生产规模的生成。企业级硬件。你不会买的——你会租。
RunPod、Lambda Labs或Modal的云实例A100大约2-4美元/小时。对偶尔用来说,比买硬件便宜。需要最终质量时开机,用完关掉。
关于本指南里的成本估算:每次生成的成本假设是在云GPU上自托管推理,A100大约2-3美元/小时或RTX 4090大约0.40美元/小时。实际成本会因硬件、优化和Batch大小而变。这些是用来做规划的大致数字——你的情况可能不同。
2026年的新东西
刚发布:LTX-2权重发布了——第一个音画同步的开源模型。Hunyuan3D 2.5现在可用,做仿真就绪的3D资源能直接在物理引擎里用。
今年要来的:亚秒延迟的实时视频生成。更好的游戏仿真世界模型。还有能在集成显卡上跑的小模型——意味着没有独立GPU的笔记本也能用。
走向很清楚:闭源模型里有的每一种能力,都会在6-12个月后出现在开源模型里。问题不是开源模型够不够好——它们对多数用途已经够好了。问题是它们多快会变成默认选项。
这对创作者意味着什么呢:那些过去需要企业预算或月费订阅的工具,正在变成你可以就……直接跑起来的东西。在你自己的硬件上。不需要别人的许可。
这就是这个转变。这就是我们在建造的方向。
更多阅读
- AI争议、信任与后AI经济 —— 我们对游戏中AI的立场
- AI生成内容政策 —— 我们如何处理AI披露
- 2026年网页游戏技术栈 —— 用于游戏的WebGL、WebGPU和Wasm
- 浏览器3D开放世界技术 —— 在浏览器世界里使用AI生成的3D资源
- 浏览器开放世界的地貌生成 —— 基于扩散的地形合成
- 哪里可以找到免费游戏资源 —— AI生成之外的传统资源来源
- Agent式AI代码工具 —— 用AI写游戏代码,不只是生成资源