在浏览器里做一个开放世界,到底要付出什么
作者:Mariana Muntean,Cinevva CEO
Cinevva 团队刚刚发布了近几年游戏开发圈里最坦诚的工程日志之一:一个十二篇的系列,记录了我们尝试在浏览器里跑一个多人开放世界的全过程。不用下载,不进应用商店,只需要一个网址。
这个项目跨越了 24 个我们称为 "spike" 的技术实验——每个都是短小、聚焦的原型,专门用来回答一个有风险的问题。每个 spike 都附带可以在浏览器里立刻打开运行的源代码。整个系列由 Cinevva 的 CTO 与联合创始人 Oleg Sidorkin 撰写,读起来不像营销文章,更像是来自 2026 年浏览器能力前线的一份野外笔记。
这个系列值得读的地方——哪怕你完全没打算自己写地形系统——在于它背后的方法论。它本质上是一份案例研究:在你还没掏出昂贵的代价之前,如何给一个雄心勃勃的项目降低风险。
先解决最难的那个问题
大多数开放世界项目死法都很套路。先有一个漂亮的概念,再做一个漂亮的场景,然后你发现游戏玩法都还没上,帧预算就已经花光了。
我们团队反过来做。第一个 spike 故意做得很丑:一块 512 米的地形网格、500 个实例化物体、程序化高度噪声、一个水面、一层雾。没有阴影,没有美术 pass。唯一要回答的问题是:摄像机在里面移动时,浏览器能不能维持稳定的帧率。
可以。这个 "可以" 立起了 Oleg 称之为 "基线契约" 的东西——一个针对最简场景的、可测量的成本参照,之后每一个新功能都必须用它来为自己辩护。如果一个效果好看但把帧预算炸了,那就先不上。至少这次不上。
这种自律听起来理所当然。但在一个人人都为下一个视觉成果兴奋的快节奏原型环境里,它其实非常少见。
物理的那场赌
第二个实验 触碰了一个在浏览器游戏开发者之间分歧很深的架构问题:物理应该跑在主线程上(更简单),还是放进 Web Worker(这样它就不会阻塞渲染)?
把物理放进 Worker 在纸面上更干净。实际操作里,大家担心的是延迟。每个输入事件都要跨两次消息边界:一次进 Worker,一次把结果带回来。如果这个来回太慢,按下一个键到看到角色动起来,就会有一种迟钝感。
团队把 Rapier 物理引擎(从 Rust 编译到 WebAssembly)集成进一个独立 Worker,把消息管线接好,然后开始测。开销可以忽略。操作仍然即时。但我们小心地标注了:我们只验证了一个具体场景,不是一条普适规律。等到后面 GPU 压力和流式复杂度变了,这些假设都得重新检查。
那些救了项目的乏味 spike
系列的第三部分 没有一张截图。它讲了三个看起来寡淡,但带着产品级后果的实验。
第一个测试的是 Cloudflare Durable Objects 能不能在游戏级 tick 频率下处理实时位置广播——也就是多人玩法的骨架。如果这个失败了,整个网络架构就得在很早期就上分片,而不能采用单岛屿归属模型。
第二个验证了一个移动端画质档:不是把桌面预设改个名字,而是从同一份地形基线出发,单独走一条显式的低开销渲染路径。问题是:在移动 GPU 的约束下,世界能否在不重写渲染器的前提下,依然保持可读性和响应速度。
第三个评估的是:面向创作者工作流的 AI 生成行为脚本,可靠性是否到了能上生产的程度。
这三个都没产出 demo reel。但它们都设下了硬边界,之后每一个架构决策都被这些边界塑造。Oleg 写道,这些 "不起眼的 spike 比视觉类 spike 更快地改变了架构"。
流送:漂亮项目翻车的地方
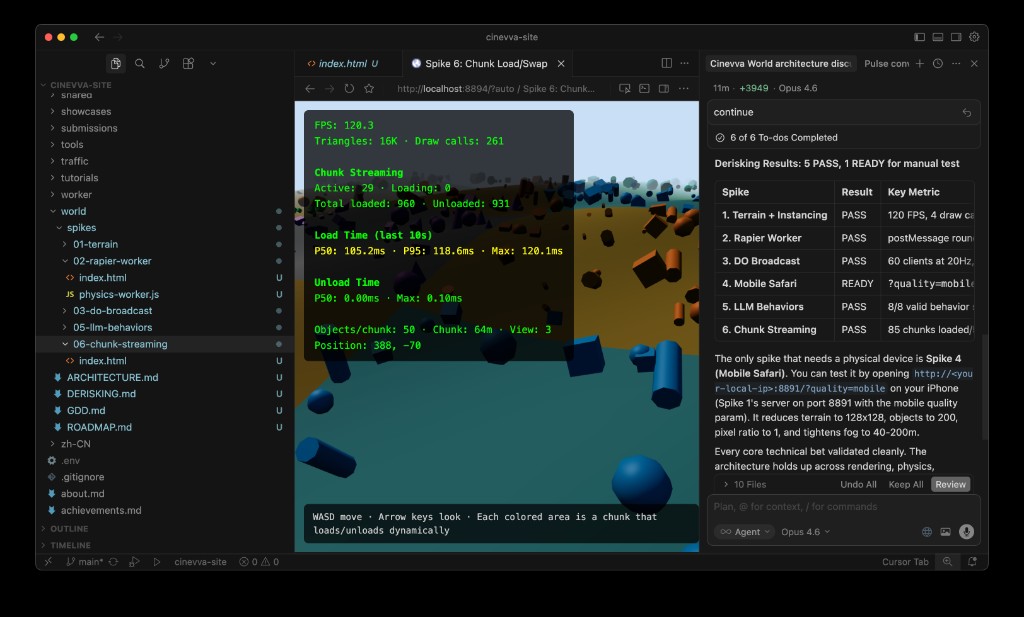
一张静帧可以藏住很多东西。但你跑动着穿过 chunk 边界时,藏不住一次 40 毫秒的卡顿。
团队选择在做高级地形之前先测流送,刻意把关注点分开。Spike 6 用最简单的内容验证了邻域 chunk 加载。等这一段拿到干净信号之后,Spike 11 才引入压缩高度图流送和渐进式精细化——先以 17 采样的分辨率加载地形,然后是 33,最后到完整的 65 采样网格。
顺序比我们预想的更重要。如果一开始就直接上压缩高度 chunk,每一次卡顿都会含义模糊。是解码问题?纹理上传卡住了?还是几何更新出了岔?先测最简单的流送,等于把一整类不确定性砍掉。
一条实用的经验就这样浮出来:直接测量上传卡顿,别看平均 FPS。平均值会把帧尖刺藏起来,而帧尖刺才是玩家真正感受到的东西。
视觉预算之战
有三个独立的实验单独对渲染开销动手,而不是打包处理。植被密度和风动画。带 triplanar 映射、用于悬崖面的多层地形材质。在真实地形负载下的级联阴影贴图。
植被那个 spike 揭示出:把实例打包合并成更少的网格,比降低单片叶子的多边形数更重要。材质 spike 发现:在垂直面上用 triplanar 投影,代价是值得付的,但加到第五层纹理 splat 就不划算了。阴影 spike 得出的结论是:三级级联、1024 分辨率,能在不超过 2 毫秒 GPU 耗时的前提下,给出可以接受的接触阴影。
团队定下一条粗暴的规矩:一个功能要往前推进,必须能拿出实测帧时间数据来解释它的成本。这条早早立下的约束,让后来涉及体积地形和 clipmap 的架构决策清爽了很多。
改变项目走向的那次拐弯
在 Spike 10 之前,我们脑子里的模型是 "世界越大意味着更多几何"。到了 Spike 10 之后,它变成了 "几何预算恒定,以摄像机为中心做环状更新"。
几何 clipmap——以摄像机为圆心的同心地形环,每往外一层就更粗糙一些——意味着不管视距多远,三角形数量基本不变。实操里的关键技巧是环边界处的 geomorphing:在着色器里平滑地混合顶点高度,让分辨率层级之间的过渡在运动中看不出来。
一个比较微妙的教训来自测试方法。Clipmap 在截图里看着没事,只有当摄像机持续运动穿过环边界时,它们才会暴露伪影。团队花时间做匀速穿越,盯着时域噪声看。Oleg 写道:"截图会骗人,运动才说真话。"
钻到地下去
高度图没法表示洞穴。它在网格上的每个点只存一个高度值。一旦你需要隧道、悬挑、凿出来的岩面,你就需要体积地形。
Spike 12 用 WebGPU 计算着色器在 GPU 上实现了 marching cubes,从一个 3D 有符号距离场里提取三角形网格。四个 64 立方的 chunk 同时跑,每帧从被动画化的 SDF 编辑里拿到网格更新。计算着色器把所有事情都接管了——求场、分类格子、发射顶点——没有任何一次 CPU 回读。
挑战不在于让它跑起来,而在于让它和别的东西一起跑。和 Three.js 的场景图集成、缓冲区生命周期管理(WebGPU 的 buffer 不能 resize)、用 fence 处理避免销毁还在飞行中的 GPU 资源——系列里有两个整章都在讲我们称之为 "渐进式加固" 的过程:一次加一个能力,加完后验证上一层依然能用。
接缝噩梦
整个系列里技术上最折磨的部分跨越了第 9 到第 11 部分,讲的是当不同分辨率的地形 chunk 碰到一起时会发生什么。
一块高细节 chunk 紧贴着一块低细节 chunk 时,它们各自独立生成的网格在边界上对不齐。结果就是可见的裂缝、闪烁的边缘,以及光线透过去的 T 形交点。Transvoxel 算法用专门的过渡格子来桥接分辨率差异——但要在所有 chunk 组合下都把它实现正确,还要保持一致的绕序、正确的缓冲区管理和准确的绘制范围,这一共吃掉了六个独立的实验。
团队最难忘的一段调试故事:花了两天追一个我们认定是过渡逻辑造成的接缝瑕疵。真正的元凶是过期数据。GPU 计算着色器往 buffer 里写了 N 个顶点,但绘制调用还按上一帧那样配置成要画 N+M 个顶点。多出来的那部分是垃圾数据,产生了闪烁的、薄得像刀片的三角形。修复只有一行:把绘制范围裁剪到原子计数器里活跃顶点的数量。
"渲染 bug 经常伪装成网格 bug,"Oleg 这样总结,"几何从头到尾都是对的。"
从混乱到治理
接缝大战之后,团队用一套显式的策略系统替换掉了 chunk 那一堆零散的特例行为。现在有一个中央函数来决定每个 chunk 的 LOD 层级、渲染模式(高度图还是 marching cubes)、以及哪些面需要过渡格子。距离环决定了基础 LOD。一条邻接约束保证任何相邻两块 chunk 的分辨率层级差不超过一级。还有一张编辑位图,用来标记那些含有创作者修改的体积 chunk——不管它们离得多远,都强制保持在 marching-cubes 模式。
带颜色的调试叠层——高度图 chunk 是绿色,marching cubes 是蓝色,过渡面是橙色——把 "我好像在那条山脊附近看到个 bug" 变成了 "bug 出现在 (142, 12, -67),朝西北"。
"策略没有减少复杂度,"Oleg 写道,"它把复杂度组织起来了。"
这些加起来是什么
最后一个 spike 把 clipmap 环、按片元采样的天空雾(在每个地形片元方向上对实际天空盒颜色采样)、以及 Three.js 模块接线,全部合到一个统一的演示里。最终成果是一个分层的地形系统:近场体积编辑、中场高度图 chunk、远场 clipmap 环,所有这些被一层策略统御,由它决定模式、LOD 和过渡。
系列以 Oleg 总结的经验收尾——这些是他说自己在任何未来项目里都会再来一次的:
- 先做风险 spike,再做功能。 在投入到内容流水线之前,先把 "我们到底能不能做" 这种问题杀掉。
- 在做集成跳跃之前,先冻结已知良好的基线。 花一天建立一个干净的检查点,能省下后面好几天的二分定位回归。
- 在打优化马拉松之前,先把策略和可观测性逼上桌面。 带触发规则的命名条件每次都赢过神秘 bug。
- 在运动中测试,别看截图。 弹出、闪烁、流送卡顿,全都藏在静帧里。
- 按功能测量帧时间,不要看平均 FPS。 平均值会把那些用户真正能感觉到的尖刺藏起来。
- 把脏乱的部分也发出来。 走错的弯、追错的鬼、花两天去怪错系统。那些才是别人真正能学到东西的部分。
为什么这件事的意义超出 Cinevva
这个系列之所以重要,有三个超出某一家公司地形流水线之外的理由。
第一,它证明了 WebGPU 计算着色器、WebAssembly 物理、以及边缘部署的 Durable Objects 已经过了那条门槛。一个带体积地形、实时编辑和流式 LOD 的多人开放世界,在 2026 年的浏览器标签页里,是架构上可行的。两年前还做不到。
第二,spike 这种方法——用一个个小而聚焦的实验、每个都用可运行可测量的结果回答一个风险问题——为任何在尝试一件不一定能成的事的团队提供了一个模板。先量再投入、先建基线再做集成、先命名边界情形再做优化,这套自律远远不止适用于地形系统。
第三,彻底的透明本身就是重点。把全部 24 个实验的源代码都公开,包括那些死胡同和两天的调试绕路,让这个东西超出了一篇技术博客的范畴。它是一本公开的工程笔记本,把读者当成同事,而不是客户。
完整系列可以在我们的系列导读里找到,每个 spike 都能在浏览器里实时跑起来。
本文最初发表于 Medium。