现代引擎如何对付植被 overdraw
作者:Oleg Sidorkin,Cinevva 联合创始人兼 CTO

森林是你能丢给 GPU 渲染的最糟糕的东西之一。每一片叶子都是一个带 alpha 蒙版的纹理四边形。几十个这样的四边形沿着每条视线方向叠在一起。光栅化器没办法提前知道哪些片元能通过 alpha 测试,所以对不透明场景帮上大忙的标准 early-Z 优化在这里基本是关闭的。结果就是:一个屏幕像素在一帧结束前,可能要把完整的叶子 shader 跑上 10 到 15 次。这就是植被 overdraw,也是过去十年里任何一款开放世界游戏帧里最贵的一块。
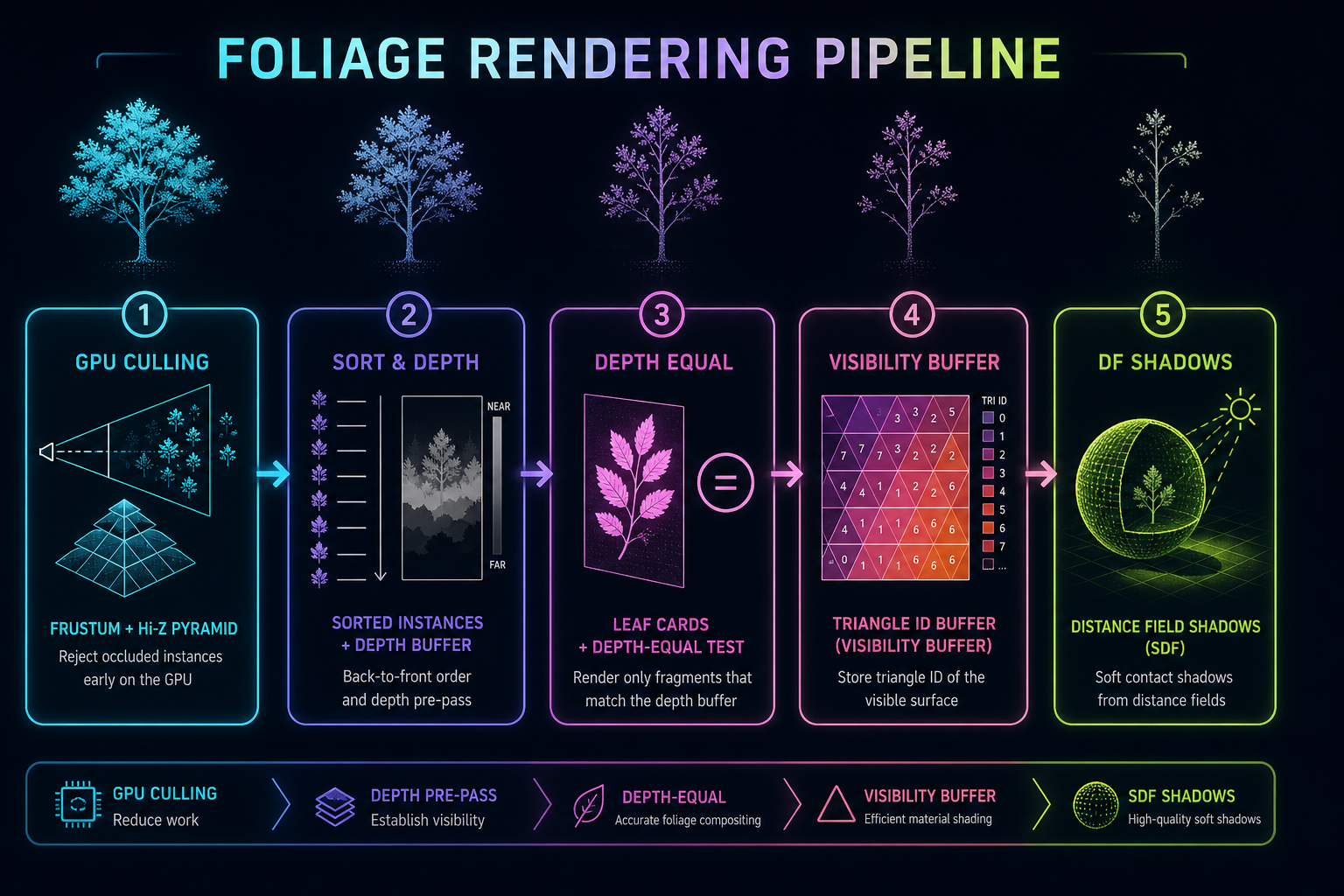
好消息是这是一个已经被解决的问题。不是说有谁靠一个技巧把它修好了,而是说有一整摞七八种技术,叠在一起,能把茂密森林里的有效 overdraw 从 8-15 倍砍到 1-2 倍。每一款现代引擎都各自实现了这套技术栈的一个版本。下面讲清楚里面都有什么、每块为什么存在、以及每块对应的经典参考。
1. 为什么植被 overdraw 这么难受
在典型的不透明场景里,GPU 会做 early depth rejection:在像素 shader 跑之前,硬件先查现有的深度缓冲,跳过已经被挡住的片元。这一步基本免费,也是密集几何成本能保持理智的根本原因。
alpha-tested 的植被把这一步打破了。片元 shader 必须真正跑起来,去读 alpha 纹理、对被蒙掉的像素调用 discard(或 clip)。硬件在 shader 跑完之前没法知道一个片元会不会被砍掉,所以在多数 GPU 上,只要 shader 里出现 discard,这个 draw call 的 early-Z 就完全失效。在基于瓦片的 GPU(移动端、M 系列、部分主机)上,它甚至可能让整帧的 Hi-Z 和深度压缩失效。每一个覆盖到一个像素的三角形都要跑一遍像素 shader,而其中大多数最后是以 discard 结尾。
把 10 片叶子的四边形叠在一个屏幕像素前面,叶子 shader 就要跑 10 遍。乘以 400 万像素,开销很残酷。Marco Salvi 那篇 To Early-Z, or Not To Early-Z 是从硬件层面解释这件事最温柔的一份介绍。如果你以前没认真想过这件事,从这里开始最合适。
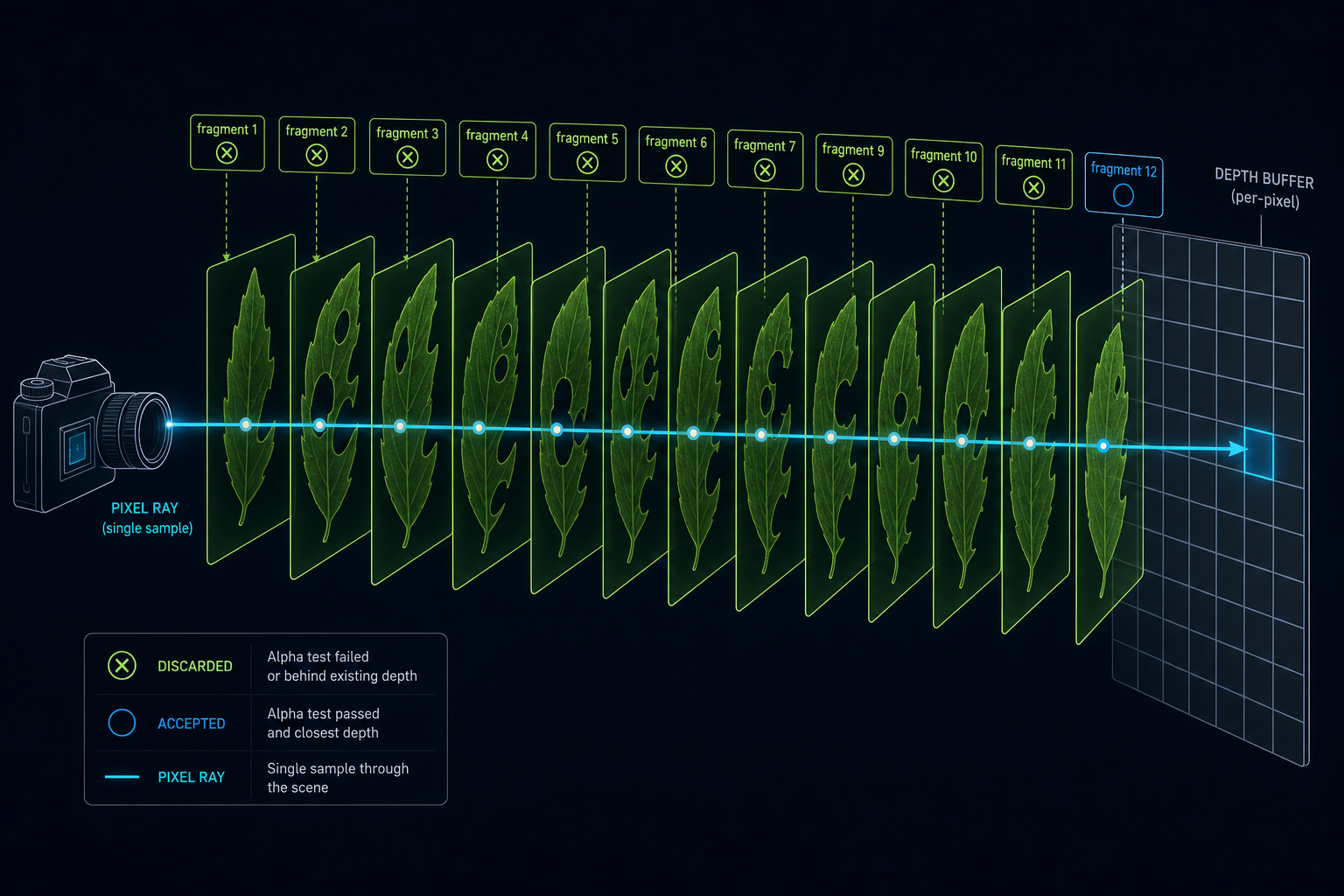
2. 给蒙版几何做深度 prepass
最大的单项收益,也是每个现代引擎都在做的事,就是把植被绘制切成两个 pass。第一个 pass 只写深度,用一个极简的 shader 做 alpha 测试、丢掉被蒙掉的像素、其他什么都不写。第二个 pass 渲染完整材质,深度测试设为"equal",关闭深度写。这样每一个可见像素都只会跑一次完整的 BRDF,不管它后面叠了多少片叶子。
这听起来像是做了双倍的活,因为你把同一批三角形碰了两次,但 prepass 的 shader 太便宜了(一次纹理采样、一次 discard、一次深度写),主 pass 节省下来的成本远远盖过了这点额外开销。茂密森林里,主 pass 不再每像素跑 10-15 次叶子 shader,而是恰好跑一次。
Unreal、Frostbite、Decima,以及现代分支的 Rage 和 Dunia 都这么干。这也是为什么在这些引擎里,蒙版材质至今都比半透明材质便宜得多。
深入阅读:
- Pettineo,To Early-Z, or Not To Early-Z(关于
discard如何与 Hi-Z 和 early-Z 互动的经典说明)。 - Wihlidal,Optimizing the Graphics Pipeline with Compute(GDC 2016,Frostbite 的深度 prepass 与 prepass 驱动的剔除架构)。
- Sanders,Between Tech and Art: The Vegetation of Horizon Zero Dawn(GDC 2018,Decima 的双 pass 植被渲染)。
- Persson,A couple of notes about Z(关于 depth-equal 测试和 prepass 经济学讲得最清楚的一篇)。
3. 激进的 LOD 与八面体 impostor
第二大收益是:能不画就别画。植被资源一般附带若干 LOD 档。最近的是含每片叶子卡片的完整网格。中距离时,叶子被合并成更密的复合卡(30 片叶子的一簇变成一张带相同剪影的纹理卡片)。超过某个距离阈值,整棵树变成一个 impostor:一小片几何,纹理是这棵树从多个角度预渲染出来的视图。
现代的 impostor 形式是 八面体 impostor:一片 8 个面的几何,纹理是用八面体映射从球面采样点采集的视图图集。运行时,shader 根据相机方向挑选最近的两到三张预渲染视图,并在它们之间做混合。结果是一个只用几个三角形的替身,从任何角度看起来都像 3D,还能正常着色、用法线贴图,甚至有风的动画。Ryan Brucks 的实现最初是社区插件,后来进了 Unreal,是这件事的参考实现。Microsoft Flight Simulator 那片有几十亿棵树的森林,除了相机附近,其它地方基本都是八面体 impostor。
更大的结构性收益是 impostor 在远处是 不透明或接近不透明 的。30 片叶子的复合卡是一张蒙版四边形,而不是 30 张四边形。整棵树的 impostor 是几个面,不是几千个。远场的 overdraw 几乎归零。
深入阅读:
- Brucks,Octahedral Impostors(经典参考,附数学和 UE 实现)。
- Halen,Octahedral Impostors in Unreal Engine(在 UE 中集成的工作流)。
- Häggström,Real-Time Rendering of Vegetation(一篇干净的论文,覆盖 LOD 链、impostor 及背后的数学)。
- Crytek,SpeedTree integration in CryEngine 3(GPU Gems 3,至今仍是树木 LOD 链最好的入门)。
4. 集群剔除与 GPU 驱动的剔除
就算有了深度 prepass,prepass 本身也是有成本的:它仍然要 碰 每一棵可见(或潜在可见)的树的每一个三角形。现代引擎用 GPU 驱动的集群剔除把这部分成本进一步压下来,在光栅化器看到三角形之前就把整组整组的三角形扔掉。
整条管线是这样的:每个 mesh 预先被切成 64 或 128 个三角形一组的 cluster,每个 cluster 有紧贴的包围盒和法线锥。渲染时,一个 compute shader 遍历实例列表,先对每个实例做视锥测试,再对每个可见实例的每个 cluster 做视锥测试,然后用上一帧的深度金字塔对每个幸存 cluster 做 Hi-Z 遮挡测试。整片整片被山挡住或被另一棵树挡住的树枝在任何顶点 shader 跑之前就被剔掉了。输出是一个紧凑的"画这些 cluster"参数列表,直接喂给一次 DrawIndirect。
这就是为什么一万棵树的森林能在几毫秒内渲染完,而不是几秒。Ubisoft 的《刺客信条:大革命》分享首次把这套管线带进生产环境(20-40% 的三角形被剔除,30-80% 的阴影三角形被剔除,屏幕上的实例数比上一代多 10 倍),Wihlidal 的 Frostbite 分享把它推得更远。UE5 Nanite 是这条轨迹的可见终点:把集群剔除一路推到像素级。
深入阅读:
- Haar 和 Aaltonen,GPU-Driven Rendering Pipelines(SIGGRAPH 2015,《刺客信条:大革命》的奠基性分享)。
- Wihlidal,Optimizing the Graphics Pipeline with Compute(GDC 2016,Frostbite 的 GPU 驱动 prepass)。
- Karis、Stubbe、Wihlidal,A Deep Dive into Nanite Virtualized Geometry(SIGGRAPH 2021,meshlet 粒度上的集群剔除)。
- Liktor,Geometry Rendering Pipeline Architecture at Activision(《使命召唤》版的集群剔除,2021)。
5. 实例与集群的"由近及远"排序
一旦 prepass 干上活,顺序 就开始变得重要。prepass 写深度,但只为通过 alpha 测试的片元写。如果你先画森林的背面、再画正面,每个正面片元都会覆盖一个背面片元,prepass 的 shader 仍然要为背面跑一遍。如果你按由近及远的顺序画,每一个后续 draw call 都会用更小的值填更多深度缓冲,Hi-Z 会在 shader 跑之前剔掉越来越多的背面片元。
这就是为什么几乎每个现代引擎都会在发出 prepass 之前按到相机距离对植被实例排序。这种排序很便宜(在 GPU 上用基数排序对几十万个实例做一次),而它把 prepass 本身变成了一个自剪枝过程。集群级的剔除也是出于同样的原因在 meshlet 粒度上做排序的。深度 prepass 与由近及远的顺序就是那种各自单独看不错、组合起来非常好的搭档。
深入阅读:
- Persson,Depth in-depth(关于深度缓冲顺序、prepass 经济学和 Hi-Z 行为的架构笔记)。
- Giesen,A trip through the graphics pipeline(关于 Hi-Z 剔除率如何依赖绘制顺序的深度技术解释)。
- Wihlidal,Optimizing the Graphics Pipeline with Compute(GDC 2016,含 Frostbite 的 GPU 端实例排序)。
6. 抖动 LOD 过渡与 hashed alpha
另一个大坑是淡入淡出。在两个 LOD 之间过渡(或随着相机靠近把一个实例淡入或淡出)最朴素的做法是 alpha blending。但混合几何不能写深度缓冲,这会把每一棵正在淡入淡出的树推到慢速的半透明路径上,并破坏 prepass。解决方案是把几何留在蒙版路径上,在 alpha 测试里 做淡入淡出。
主要两种技术:
- 抖动 LOD 过渡 采样一张 4x4 或 8x8 的 Bayer 模式(或屏幕空间的蓝噪声纹理),把它作为每像素的截断阈值修正。混合度为 50% 的树会留下一个棋盘格状的存活像素;缺失的像素由下一个 LOD 互补的棋盘格填上。TAA 把棋盘格在两三帧里平滑成顺滑的混合。便宜、稳定、与引擎其余部分都能搭。
- Hashed alpha testing(Wyman & McGuire,I3D 2017)把固定的 0.5 alpha 阈值替换为每像素 [0,1) 的哈希阈值。本该完全消失的远处 alpha 几何(因为 mipmap 后的 alpha 掉到了 0.5 以下)能保持一片稳定散布的存活像素。同样靠 TAA 收尾。
两种技术都把植被留在不透明/蒙版路径上,让深度 prepass 仍能工作,你就不用为了淡入一个东西付出全套半透明渲染的代价。Alpha to coverage 是同一思路在 MSAA 时代的表亲:把 alpha 转成子像素覆盖率掩码,在不离开蒙版路径的情况下得到部分透明。代价是 A2C 只有在 MSAA 上才真正出彩,而现在大多数现代延迟渲染管线都不再用 MSAA 了。
深入阅读:
- Wyman 和 McGuire,Hashed Alpha Testing(I3D 2017,hashed alpha 的经典论文)。
- Castaño,Computing Alpha Mipmaps(The Witness 博客,对 alpha-tested 纹理生成 mipmap 的正确做法,避免远处的树消失)。
- Yuksel,Alpha Distribution for Alpha Testing(对 alpha mipmap 的更近期改进)。
- NVIDIA,Anti-Aliased Alpha Testing(A2C、hashed alpha 和抖动方案的综述)。
7. 降低蒙版像素的着色成本
就算有完美的 prepass 和完美的剔除,每个可见的植被像素仍然要被着色一次。引擎也会把这部分成本压下来:
- 更便宜的 BRDF。植被是哑光的,并不需要完整的 Cook-Torrance 镜面反射通路。一个 wrapped-Lambertian 漫反射加上一行近似镜面已经够用。
- 更低频的法线贴图。叶子本身就很乱。在常见观看距离下,256x256 的法线贴图和 1024x1024 看起来一样,还能省带宽。
- 不用视差、不用各向异性、不用 clearcoat。叶子上的 PBR 功能菜单全部关掉。
- 双面薄物体透射 代替完整的次表面散射。叶子会从背面透光,但你可以用一个反向光照点积来模拟。
- 半分辨率着色,部分引擎里。植被以 1/4 或 1/2 像素率着色后再上采样。TAA 的随机噪声会掩盖重采样。
- 默认跳过细节贴图和贴花 在蒙版材质上。
每一项单独看都只是小赢。组合起来,蒙版植被 shader 可以比对应的不透明材质快 2-3 倍。
深入阅读:
- Lagarde 与 de Rousiers,Moving Frostbite to Physically Based Rendering 3.0,关于植被和透射的章节(SIGGRAPH 2014,针对薄双面材质的 PBR 经典调整)。
- Jimenez,Next Generation Character Rendering(wrapped-Lambertian 和背面透射的数学,原本是为皮肤做的,被广泛移植到了叶子上)。
- Sanders,Between Tech and Art: The Vegetation of Horizon Zero Dawn(GDC 2018,Decima 的植被 shader 简化)。
8. 可见性缓冲与 Nanite 对蒙版材质的支持
对付 overdraw 最干净的答案是 把着色和光栅化彻底解耦。可见性缓冲把几何光栅化到一张薄薄的缓冲里(每像素只存三角形 ID 和实例 ID),然后跑一个延迟通路读这张可见性缓冲,对每个像素恰好着色一次。根据构造,着色阶段没有任何 overdraw。Burns 和 Hunt 2013 年的论文提出了这个思路;UE5 Nanite 是它的生产级实现,自 UE 5.5 起也包括蒙版植被。
Nanite 的妙处在于它把这件事和集群级虚拟化几何结合起来,光栅化器本身对亚像素三角形走软件路径,让 overdraw 有界。Nanite 里的蒙版材质需要"可编程光栅化"特性:alpha 测试在可见性缓冲通路里跑,但材质着色仍然在延迟解析里对每个可见像素跑一次。结果是非常密集的 Nanite 植被——以前在蒙版材质上以慢著称——现在和不透明材质有得一比,甚至更便宜,因为着色时的 overdraw 是零。这里有个取舍:把高多边形的 不透明 树几何丢进 Nanite,往往比保留低多边形的蒙版卡片树要划算,因为蒙版路径要额外付出可编程光栅化的成本。
深入阅读:
- Burns 和 Hunt,The Visibility Buffer: A Cache-Friendly Approach to Deferred Shading(JCGT 2013,原始论文)。
- Karis、Stubbe、Wihlidal,A Deep Dive into Nanite Virtualized Geometry(SIGGRAPH 2021,生产级架构)。
- Epic,Nanite GPU Driven Materials(GDC 2024,含蒙版材质与可编程光栅化管线)。
- Notes from "Nanite GPU Driven Materials"(同一场分享的第三方整理)。
9. 给植被专门的阴影表示
在任何开放世界帧里,alpha-tested 植被的阴影贴图是仅次于大级联的第二贵阴影问题。每个级联都要自己的深度 prepass,每个 prepass 都要跑 alpha 测试,4 个级联和几十个光源视锥叠起来代价就累上去了。所以多数引擎不会用渲染植被颜色的同一套方式去渲染植被阴影。
常见的替代方案:
- 网格距离场阴影(UE Lumen、自研引擎)。每个网格都有预先计算的有符号距离场。在 SDF 上做一次短锥形追踪就能得到一片柔和阴影,全程都不碰 alpha-tested 网格。对树尤其友好,因为 SDF 把树冠的剪影当作一整块固体来捕捉,忽略每片叶子的细节。
- 植被用更低分辨率的级联。植被阴影进入半分辨率的切片,用感知边缘的滤波上采样回来。眼睛看不出分辨率下降,因为阴影本来就柔。
- 带 MSAA 的 alpha-to-coverage 阴影贴图。在还保留 MSAA 阴影路径的引擎上,A2C 能在不付出完整 alpha 测试代价的情况下得到边缘平滑的植被阴影。
- 树干和大树枝用胶囊阴影,树冠用距离场,只有最近的级联才走完整 alpha 测试。不同距离用不同的表示,在光照通路里混合。
- WPO 禁用距离。风驱动的 World Position Offset 在某个阈值之外被关掉,让缓存的阴影数据跨帧仍然有效。UE 的 Virtual Shadow Maps 严重依赖这一点。
深入阅读:
- Epic,Distance Field Soft Shadows in Unreal Engine(UE 网格 DF 阴影的经典参考)。
- Wright,Lumen: Real-Time Global Illumination in Unreal Engine 5(SIGGRAPH 2022,Lumen 对植被的网格 SDF 集成)。
- Epic,Virtual Shadow Maps(现代 UE5 阴影架构,含针对植被的 WPO 禁用与缓存规则)。
- Persson,Practical Cascaded Shadow Maps(至今仍是经典的 CSM 参考,含关于 alpha-tested 投射者的笔记)。
10. 风、动画与阴影缓存
一个相关的微妙问题:大多数植被会动。风驱动的顶点动画(UE 里的 World Position Offset,Frostbite 和 Decima 中对应的实现)意味着植被几何并不跨帧稳定,这会破坏阴影缓存和重投影。现代引擎从两方面来对抗这件事:
- 远距离截断 WPO。在某个阈值之外,风动画的幅度平滑地降到零。那么远的地方眼睛本来也看不到摇晃,阴影缓存就保持有效。
- 把风烘进 cluster 包围盒。cluster 的包围盒按最大 WPO 偏移做扩大,让剔除保持保守,不必每帧重新上传。
- 逐实例的相位偏移。同样的树用一个逐实例的随机种子来错开风的相位,让森林不会步调一致地摇,而且也不必为每棵树付出唯一动画的代价。
这类细节通常不会出现在技术列表里,但在实战里就是 3 ms 森林和 9 ms 森林之间的差距。
深入阅读:
- Sanders,Between Tech and Art: The Vegetation of Horizon Zero Dawn(GDC 2018,Decima 的风动画管线与阴影缓存)。
- McAuley,Rendering the World of Far Cry 4(GDC 2015,含针对植被的风网格采样)。
- Epic,Foliage and Virtual Shadow Maps(UE5 社区对 WPO 禁用距离和 VSM 缓存的指引)。
11. 组合起来算账
这些技巧没有一个是银弹。有意思的是把它们叠起来会发生什么:
- 在密林场景里,朴素的蒙版植被通路有效 overdraw 是 8-15 倍。每个可见像素跑 8 到 15 次叶子 shader。
- 加上深度 prepass,主 pass 的 overdraw 降到 ~1 倍,但 prepass 本身仍然要碰所有东西。
- 加上由近及远的排序,prepass 开始自我剪枝。
- 加上集群级的 GPU 剔除,prepass 只碰可能可见的部分。
- 加上 LOD 链和 impostor,30 米外可见四边形的 数量 整整下降一个数量级。
- 加上可见性缓冲 / Nanite 路径,即便密集重叠,着色阶段真正每像素只跑一次。
- 加上距离场阴影,阴影成本不再随 alpha 测试规模线性增长。
上面这些分享里反复出现的标题级结论是:有效 overdraw 从 8-15 倍塌缩到 1-2 倍,整体植被帧时间在密林场景里下降 4-6 倍。这就是现代开放世界游戏能在消费级硬件上以 60+ fps 渲染森林的全部原因。
12. 这对浏览器意味着什么
这套技术栈的大部分能干净地映射到 WebGPU 上。我们已经在 浏览器开放世界引擎 中上线了 GPU 驱动的剔除、间接派发、Hi-Z 遮挡,以及由近及远排序的 prepass。蒙版几何的深度 prepass 直接就行:WebGPU 支持 depth-equal 测试和片元 shader 里的 discard,关于 early-Z 的注意事项也一样。八面体 impostor 可以机械地移植过来,数学不过是球面到八面体的展开和图集索引。
更难的是那些更现代的部分。WebGPU 里实现可见性缓冲意味着把 32 位的三角形 ID 写进一个渲染目标,再用一个全屏 compute pass 解析材质;基础积木都在,但编排比较费力。网格距离场阴影需要每个资源一张 3D 纹理和一次短锥追踪,这两件事都在 WebGPU 的射程之内。Hashed alpha 和抖动 LOD 各自只是一个 shader 函数。
浏览器植被往前走的路和这套技术栈里的其它部分一样:先上便宜、稳健的部件(prepass、排序实例、LOD、impostor、hashed alpha),再在上面加重型机器(可见性缓冲、网格 SDF 阴影)。浏览器端硬件下限终于高到没有结构性原因让 WebGPU 的森林看起来或跑起来不像主机。剩下的全是工程上的原因,而工程上的原因正是我们喜欢的那种。
跨整套技术栈的延伸阅读
如果你想要一份把所有内容串起来的资料,SIGGRAPH "Advances in Real-Time Rendering in Games" 档案(advances.realtimerendering.com)里收录了 2014 年以来植被与 GPU 驱动渲染的经典分享。Adrian Courrèges 的 GPU 性能剖析文章 包含对 GTA V 和 Horizon Zero Dawn 的逐帧拆解,把这里讨论的每个通路按生产顺序展示出来。专门讲 alpha 测试的数学,Chris Wyman 的 研究页面 有 hashed alpha 与随机透明的论文,附参考 shader。还有 Real-Time Rendering, 4th edition 关于透明、采样和深度处理的章节,至今仍是教材级起点。