从草图到视频到可玩 3D
作者:Oleg Sidorkin,Cinevva CTO
把一个角色从一张平面草图做到一个可玩的 3D 游戏,过去需要一个概念美术、一个 3D 模型师、一个绑骨师、一个动画师,再加一个把它们在引擎里串起来的人。我们想看看 Cinevva 的创作工具自己能扛下这条管线的多少。下面是结果。
角色是 Cubcoats 的 Kali the Kitty,一个儿童品牌,在 Nordstrom、Amazon、Disney Store 卖出过百万件毛绒玩偶卫衣。Cubcoats 有八个原创角色,每个都有自己的性格设定,一个虚构的岛屿世界,14 项专利。他们正以"授权优先"的平台姿态在 2026 年重新出发,我们想展示这套 IP 走出实物产品之后会是什么样:一个竖屏短视频,加一个你能在浏览器里走来走去的绑骨 3D 角色。下面所有东西都是那次探索的真实产出。
3D viewer 用鼠标拖动来环视。下面的胶片条拖动一下能看到竖屏短片从第一帧到最后一帧的运动。
从平面书本插画到一个能转着看的角色
Cubcoats 本来就有漂亮的 2D 插画。Mimi Chao 的美术方向给每个角色一种温暖、圆润、手绘感的样子,放在卫衣和绘本上很合适。但平面美术喂不了 3D 管线。我们需要一个高保真度的角色,能站得住作为视频生成、mesh 生成、绑骨的参考——全部从同一张脸来。
我们一开始把原版书本插画喂给我们的图像生成器,让它产出同一个角色的 3D 渲染版本。

比例稳住了,性格出来了,柔和的 3D 卡通感给了下游每个工具一个一致的参照。从那里我们继续迭代具体姿势和构图,直到锁定一个英雄参考。


T-pose 重要,因为绑骨期望手臂离开躯干。跳过的话自动绑骨会把手臂融进身体然后放弃。我们用同一套锁定角色样式生成 T-pose,让剪影和比例每一步都保持一致。
在生成任何东西之前先写故事
碰视频工具之前,我们用大白话写了一份分镜。Kali 在 Cubcoats 宇宙里的人物性格是"Positive"。她是那个让所有人感到被包含的人,事情变难的时候保持向上。所以我们围着这个做了一个十秒的弧线:
Kali 走进一片黑暗的雾林,是夜晚,手里捧着一个小小的发光提灯。她害怕了,独自坐下,几乎要放弃。然后她发现身后亮起了一棵神奇的金色大树。惊奇、喜悦、金色粒子像雨一样洒下来。从恐惧到希望,一口气之间。
整个剧情就这些。不需要复杂。它需要把一个情绪转折塞进一个连贯镜头里,这样起始帧和结束帧才能真的连上。
把整件事框住的两帧
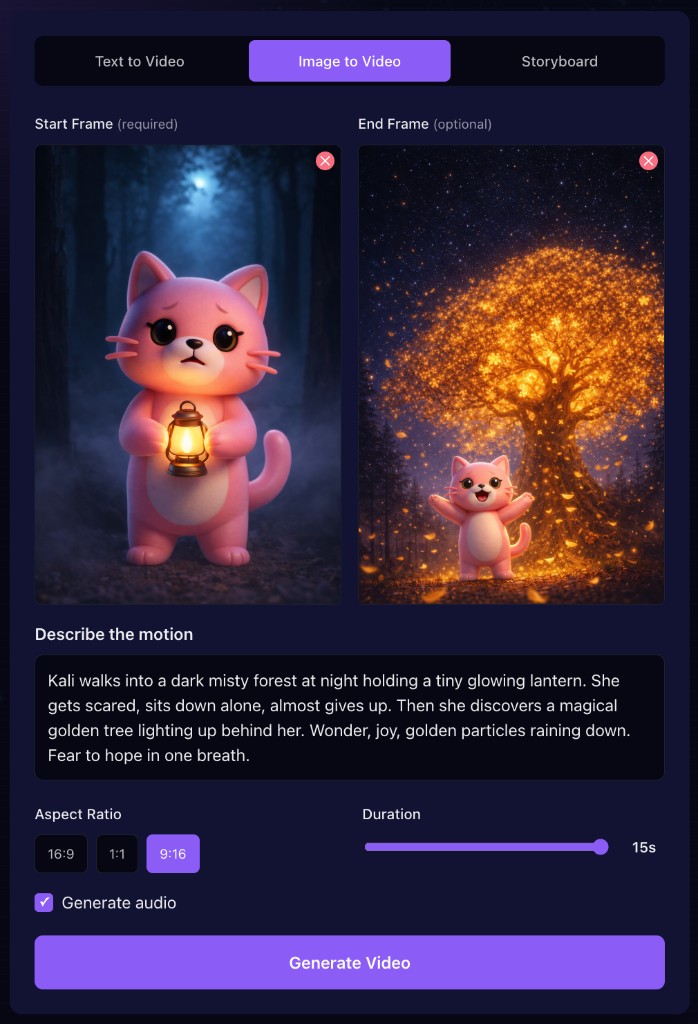
我们用图像生成器从这个剧情生成了两张关键静帧。竖向比例匹配竖屏短片。两个 prompt 描述了完全相同的角色在两个不同时刻的样子。
起始帧 prompt:
3D animated Pixar-style render of Kali, a small pink kitty character with large round dark eyes, pink pointed ears, a light pink belly, and a cheerful round face. She is standing at the edge of a dark misty forest at night, holding a tiny glowing lantern in both paws. Her ears are slightly flattened and her expression is nervous but determined. Cinematic lighting with cool blue moonlight from above and warm orange glow from the lantern. Dense fog between dark tree trunks in the background. Camera angle: medium shot, slightly low looking up at her. No text, no watermark.
结束帧 prompt:
3D animated Pixar-style render of Kali, a small pink kitty character with large round dark eyes, pink pointed ears, and a light pink belly. She is standing in front of a massive magical tree covered in glowing golden flowers, arms outstretched wide, beaming with a huge joyful smile. Golden petals float in the air around her. The tree radiates warm golden light that illuminates the entire forest clearing. Starry night sky visible above. Camera angle: wide shot from slightly below, epic reveal composition. No text, no watermark.


Seedance 在这两个端点之间做插值。两个 prompt 里角色描述完全一致,让模型知道是同一个人。变的只有场景、情绪和相机。
视频出来比预期的好
我们把两张帧加载进 Cinevva 的视频生成器,选了 Seedance 1.5 Pro,设 9:16 比例 15 秒,把剧情敲进动作 prompt,点 Generate。
片段在两个端点之间插值。原生音频在同一遍里生成。这是沿时间线采样的几帧。









从左到右:生成的竖屏短片的进度。
要打到一个精确的收尾姿势时,起始帧加结束帧是对的模式。更长的情绪弧线,单参考加 prompt 在视频生成器的 Kling 3.0 Pro 故事板模式下效果不错。不同活用不同设置。
同一个角色,现在变成 3D
有意思的部分来了。和视频参考同一家族的 T-pose 静帧给了我们的 3D 模型生成器做图到 3D 生成。你不是把游戏 mesh 和视频做像素级匹配。你匹配的是玩家记忆。游戏里的角色应该感觉是和短片里同一个性格。因为我们一开始就锁定了一个视觉身份,所以做到了。

3D 模型生成器输出一个带贴图的 GLB。不是游戏可用级别,但能认出是 Kali。剪影对得上。材质接近。够好,可以往下走。
拖一拖这两个
3D 模型生成器的原始输出。没绑骨,只是一个带贴图的 mesh。旁边是同一个角色自动绑骨之后,带一段烤好的走路动画。
绑骨和动画
3D 模型生成器给你一个 mesh。要让这个 mesh 动起来,它需要骨架和动画。我们的平台自动处理绑骨:上传 GLB,回来一个绑了骨的模型,带完整的动画库。走路循环、待机呼吸、跳跃,一个游戏角色需要的全有。
默认走路动画看上去差不多对了,但不完全。Kali 的手臂离身体太近,头的倾斜角也有一点不对。这对通用人形是合理的,但放在一个圆圆的卡通小猫上就感觉怪。所以我们在游戏代码里加了运行时骨骼修正:一个肩部偏移把手臂往外推,一个头部旋转修正把倾斜扶正。小调整,大差别。没有这些她看上去僵硬像机器人。有了之后她又像 Kali 了。
在浏览器里玩这个角色
我们把绑好骨的模型扔进 Cinevva 引擎。第三人称相机、WASD 移动、四处撒的可收集物、待机时的环绕镜头。把动画混合调对花了一些迭代:在 idle 和 walk 之间淡入淡出,把高度归一化,修正前向轴,调骨骼偏移。第三人称相机跟在角色身后,从草图到能走来走去的东西的闭环完成。
自己试试。WASD 移动。
如果有人明天要做这件事,我会跟他说什么
碰任何生成工具之前先锁定一个角色样式。你花在把那张参考做对上的每一分钟,省掉之后追一致性的一小时。
先写一个小剧情。然后用图像生成器生成你的起始帧和结束帧。参考图保持在 API 大小限制内。喂 3D 模型生成器时用同一套设计体系下的 T-pose。
把两张帧喂给视频生成器,让它插值。游戏 mesh 那一边,通过平台给模型绑骨,如果默认动画跟你角色的比例不太合,运行时调一下骨骼偏移。
两年前,这条管线不存在。你得有一个团队和一笔预算。现在你需要的是一张草图和 Cinevva 的创作工具。我觉得这是关于"谁能让一个角色活起来"的一个有意义的变化。
用到的 Cinevva 工具:图像生成器、视频生成器、3D 模型生成器、自动绑骨,以及 Cinevva 引擎。反映 2026 年初。